
Au fil des décennies, le secteur de la traduction a proposé l'utilisation de traductions « similaires » dans les outils de TAO, permettant aux traducteurs humains de visualiser une ou plusieurs correspondances extraites d'une mémoire de traduction (TM) lors de la traduction de nouveaux documents. Une mémoire de traduction (TM) est une base de données qui stocke des segments de texte et leurs traductions correspondantes. Les segments peuvent être des phrases, des paragraphes ou des unités semblables à des phrases (en-têtes, titres, éléments d'une liste, etc.). Bien que la situation idéale soit de trouver des correspondances parfaites, celles-ci ne sont pas toujours disponibles. Dans ce cas, les traducteurs ont recours à des correspondances présentant suffisamment de contenu en commun avec le document à traduire. Ces correspondances partielles sont alors légèrement « réparées » pour obtenir des traductions correctes.
L'utilisation des correspondances de TM repose sur l'idée que la réparation d'une correspondance de TM donnée nécessite moins d'efforts que la production d'une traduction à partir de zéro, ce qui conduit à une productivité et à des taux de cohérence plus élevés. La figure suivante illustre la traduction humaine via la réparation d'une correspondance TM. La phrase anglaise Combien de temps dure le vol ? est traduit en français compte tenu de la correspondance TM Combien de temps dure une grippe ? – Quelle est la durée d’une grippe?
Les étapes suivantes :
- Identifier les incohérences entre la phrase d'entrée et la correspondance TM : le vol – une grippe.
- Traduire en contexte la séquence manquante de la phrase d'entrée : le vol – le vol.
- Intégrer la traduction de la séquence manquante précédente dans la correspondance TM pour compléter la traduction de la phrase d'entrée. L'intégration implique généralement l'élimination des incohérences dans la correspondance TM : une grippe, en vérifiant la concordance des mots et en vérifiant la signification globale de la traduction obtenue : le vol – du vol.

Par le passé, les correspondances TM ont été intégrées de manière transparente dans Statistical MT (SMT). Les deux, SMT et le processus de réparation suivent la même idée simple de composer la traduction via une combinaison optimale de longues pièces de traduction arbitraires. En revanche, l'intégration est moins évidente dans le cas de la traduction automatique neuronale (NMT) car les réseaux de traduction ne conservent ni ne construisent une base de données de séquences alignées, et ils opèrent sur une représentation distribuée de mots plutôt que sur des unités discrètes.
Notre travail montre comment nous pouvons exploiter une TM en enseignant un modèle NMT pour intégrer des traductions similaires de la même manière qu'un humain considère qu'une TM correspond. De plus, nous évaluons différentes méthodes pour récupérer des phrases « similaires ».
Mesurer la similarité des phrases
De nombreuses méthodes de calcul de la similarité des phrases ont été explorées dans le passé, principalement en se divisant en deux grandes catégories : les correspondances lexicales (c'est-à-dire les correspondances floues) et la sémantique distributive. Le premier repose sur le nombre de chevauchements de mots entre les phrases prises en compte. Ce dernier compte sur le pouvoir de généralisation des réseaux neuronaux pour construire des représentations vectorielles distribuées. La figure suivante illustre la similitude de la phrase : Combien de temps dure le vol ? a) en deux phrases : Combien de temps dure une grippe ? b) et Quelle est la durée du vol ? c) en suivant la correspondance floue (gauche) et les représentations vectorielles distribuées (droite).
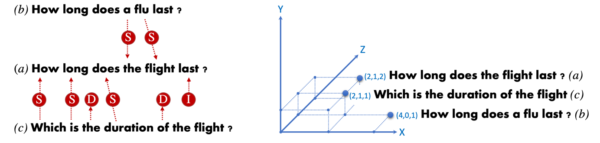
Notez que la phrase suivante représentations distribuées, phrase c) est plus proche de a) que la phrase b). Cette approche remarque la similarité sémantique entre Combien de temps dure-t-il et Qui est la durée de bien qu'il n'ait pas partagé de mot. La distance de correspondance floue est calculée en mesurant le nombre de (S)substitutions, (I)insertions et (D)élections nécessaires pour convertir une phrase en l'autre. Dans le cas de la sémantique distributionnelle, la distance cosinus entre les représentations vectorielles de phrase est typiquement utilisée.
Amorçage de Neural MT avec correspondances TM
L'amorçage est un phénomène de psychologie bien connu et étudié basé sur la présentation préalable d'un stimulus (cue) influer sur le traitement d'un réponse. La figure suivante illustre l'amorçage humain. L'être humain doit prédire la forme complète d'un mot qui manque une lettre so_p. Sans amorçage (à gauche), l'humain considère deux options comme tout aussi probables, savon et soupe, alors qu'après avoir été apprêté avec des mots dans le domaine sémantique de ?foods ? (à droite) l'humain considère plus probable le mot soupequi appartient également au même champ sémantique.
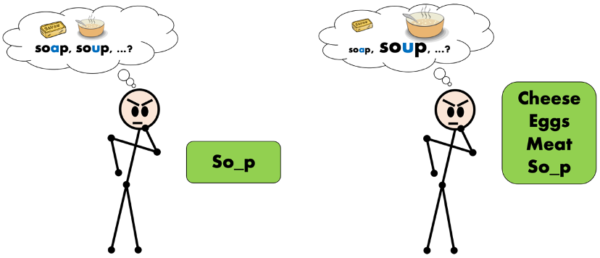
Notre travail suit une stratégie similaire pour amorcer un réseau de traduction automatique neuronale avec des traductions similaires obtenues à partir d'une TM. Nous utilisons les mesures de similarité précédemment détaillées et évaluons plusieurs approches pour amorcer le réseau à l'instant d'inférence, sans adapter les paramètres du réseau.
Voyons d'abord comment la traduction est effectuée par un réseau NMT suivant l'architecture Transformer. La figure suivante illustre une version simplifiée de l'inférence de traduction pour la phrase saisie Combien de temps dure le vol ?

Le module codeur initial est chargé de construire la représentation d'enrobage des mots d'entrée, encodant ainsi des mots d'entrée dans des vecteurs d'entrée (blocs gris). Une fois toute la phrase d'entrée lue, le module de décodage effectue mot à mot la génération de l'hypothèse de traduction. Notez que lors de la génération de mots traduits, le décodeur prête attention aux mots d'entrée (arcs gris) ainsi qu'aux mots précédemment traduits (arcs verts). Ce mécanisme d'attention vise à se concentrer sur des mots spécifiques qui contribuent notamment à la génération du prochain mot de traduction. Technique particulièrement utile pour des séquences plus longues
Nous détaillons maintenant différentes façons d'injecter des indices d'amorçage (correspondances TM) dans le réseau Transformer. Le premier schéma est présenté par (Bulté et Tezcan, 2019) et modifie le flux d'entrée en concaténant la traduction similaire trouvée sur la TM correspondent à la phrase d'entrée. Par conséquent, le flux d'entrée résultant se compose de deux phrases chacune dans une langue différente. La figure ci-dessous illustre le schéma. Le décodeur a maintenant accès à la correspondance TM (arcs bleus), qui guide le décodeur lors de la génération de mots cibles.

L'approche permet d'obtenir des gains de précision importants lorsque des phrases similaires sont disponibles dans la TM. Cependant, une déficience est également observée concernant les mots non apparentés. Nous faisons référence à des mots non liés comme étant les mots de la TM qui correspondent et qui ne doivent pas être utilisés dans la traduction (dans notre exemple précédent d’une grippe sont des mots sans rapport). Dans certains cas, le réseau de traduction devient confus et copie également des mots sans rapport dans la traduction actuelle. Le problème est particulièrement important lorsque des mots sans rapport sont sémantiquement proches des mots de la bonne traduction. Imaginez, par exemple, lors de la traduction du flux d'entrée :
![]()
Bien qu'il s'agisse d'un mot sans rapport, voyage [trip] est sémantiquement proche de la traduction correcte du vol, volet son apparition dans le flux source encourage le réseau à l'utiliser dans la traduction de la phrase d'entrée.
Dans (Xu, Crego et Senellart, 2020), nous avons proposé la première solution à ce problème. Il consiste à utiliser un deuxième flux d'entrée (caractéristique) pour informer le réseau de la nature de chaque mot: mot de la phrase d'entrée (0); mot de la correspondance TM lié à la phrase d'entrée (1); et mot de la correspondance TM non pertinent pour traduire la phrase d'entrée (2)

Chaque flux est codé dans sa propre représentation vectorielle qui est ensuite concaténée pour obtenir un seul vecteur pour chaque mot d'entrée. Le reste du réseau reste inchangé. Nos résultats indiquent une nette réduction du nombre de mots sans rapport apparaissant dans les traductions.
Dans (Pham, Xu, Crego, Senellart et Yvon, 2020) nous suivons un autre schéma pour injecter des indices d'amorçage dans le réseau Transformer. Dans le but d'atténuer davantage le problème des mots non liés, nous indiquons maintenant au réseau les deux côtés de la correspondance TM. Nous concaténons la partie source de la correspondance à la phrase d'entrée tandis que la partie traduction de la correspondance est maintenant transmise au réseau sous la forme d'un préfixe de décodeur (bleu). Le préfixe est imposé à la recherche de faisceau qui s'effectue en mode de décodage forcé. La figure suivante illustre ce schéma. Le décodeur produit la traduction (vert) en prêtant attention aux mots sources de correspondance TM en plus des mots de traduction de correspondance TM (arcs bleus) et des mots de phrase d'entrée.

Ce schéma permet d'obtenir les meilleurs résultats en termes de précision de traduction et de réduire davantage l'utilisation de mots non liés des schémas précédents. En utilisant les deux côtés de la correspondance, nous facilitons l'apprentissage en réseau des mots similaires (bleu) nécessaires lors de la traduction de la phrase d'entrée. Notez que ce schéma permet de séparer les vocabulaires des codeurs et des décodeurs.
Le tableau des résultats ci-dessous et les documents cités en référence contiennent de plus amples détails. Ces travaux de recherche ouvrent la voie à une intégration profonde de la traduction automatique neuronale et de la TDM outils utilisés par les traducteurs professionnels. Nos ingénieurs travaillent maintenant d'arrache-pied pour que cette fonctionnalité soit disponible pour tous nos utilisateurs.
Références :
- Neural Fuzzy Repair : Intégration des correspondances floues dans la traduction automatique neurale. Bram Bulte, Arda Tezcan. ACL 2019.
- Stimuler la traduction automatique neuronale avec des traductions similaires. Jitao Xu, Josep Crego, Jean Senellart. ACL 2020.
- Amorçage De La Traduction Neuronale Automatique. Minh Quang Pham, Jitao Xu Josep Crego, Jean Senellart, François Yvon. WMT 2020.





