
Cet article est paru à l’origine sur Kirti Vashee’s Blog.
Il existe certains types d'applications de traduction où MT est tout simplement logique, et il serait stupide de même tenter ce genre de projets sans une technologie MT décente comme base. En général, cela est dû au fait que ces applications présentent une combinaison des facteurs suivants :
- Très grand volume de contenu source qui ne pouvait tout simplement PAS être traduit sans MT dans un délai utile
- Délai d'exécution rapide (jours, heures ou minutes) nécessaire pour que le contenu ait une valeur pour les utilisateurs de la traduction
- Une tolérance de l'utilisateur pour des traductions de moindre qualité au moins dans les premières étapes de l'examen des informations
- Permet de trier les informations et les documents lorsque vous traitez des collections de documents volumineuses et d'identifier le contenu prioritaire à partir d'une masse importante de contenu non différencié. Ce processus permet également d'identifier les documents les plus importants et pertinents à envoyer à une traduction humaine de meilleure qualité.
- Interdictions de coûts de traduction (généralement liées au volume)
On peut trouver cette combinaison d'exigences dans plusieurs applications orientées vers la communication client comme la base de connaissances du support technique, les listes de produits eCommerce, le service client et les revues CX pour tous les types de produits et d'expériences de service. Cependant, dans un monde de plus en plus numérique, nous voyons la nécessité de pouvoir traiter de grands volumes de contenu d'entreprise afin d'identifier ce qui est le plus pertinent et le plus précieux pour les besoins de la mission commerciale continue. L'eDiscovery est l'une de ces applications de triage des informations métiers. Depuis que je travaille avec MT, j'ai constaté qu'il s'agit d'un besoin continu qui continuera de prendre de l'ampleur à mesure que nous devenons des travailleurs axés sur le numérique.
SYSTRAN a été un leader parmi les fournisseurs de solutions MT dans le segment eDiscovery, et a une longue expérience de succès dans ce segment, et de mon point de vue, une plus grande sensibilité aux besoins des clients de ce segment que la plupart des autres. Récemment, ils m'ont donné un accès sans entrave à quelques-uns de leurs clients eDiscovery, qui m'ont donné un aperçu de ce qui compte vraiment en termes de MT du point de vue de l'utilisateur. Cet article décrit certaines exigences clés du point de vue d'un utilisateur actif, en particulier : Alvarez et Marsal à Londres. En particulier, leur volonté de partager leurs idées m'a permis de fournir et de valider mes propres observations faites dans le fond de ce billet. J'ai aussi eu un billet précédent de iQwest qui décrivait également l'utilisation de MT dans les applications eDiscovery du point de vue du fournisseur de services.

Qu'est-ce que l'eDiscovery ?
Découverte électronique (parfois appelé e-discovery, e-Discovery ou e-Discovery) est le électronique aspect de l'identification, de la collecte et de la production d'informations stockées électroniquement (ESI) en réponse à une demande de production dans le cadre d'une action en justice ou d'une enquête interne. ESI comprend, sans s'y limiter, les courriels, les documents, les présentations, les bases de données, la messagerie vocale, les fichiers audio et vidéo, le contenu des médias sociaux et les sites Web.
Les processus et les technologies entourant l'e-discovery sont souvent complexes en raison du volume et de la variété des données électroniques produites et stockées. De plus, contrairement aux preuves sur papier, les documents électroniques sont plus dynamiques et contiennent souvent des métadonnées telles que les horodatages, les renseignements sur l'auteur et le destinataire et les propriétés des fichiers. La préservation du contenu et des métadonnées d'origine pour les informations stockées électroniquement est nécessaire afin d'éliminer les allégations de spoliation ou de falsification de preuves plus tard dans un scénario de litige.
En règle générale, dans un scénario d'e-discovery, lorsqu'une masse de documents est initialement importante, les activités suivantes sont exécutées pour organiser et identifier les documents les plus importants à partir d'une masse de documents importante (Pas sûr que ce soit tout un corpus ? en général il est beaucoup trop déstructuré pour l'appeler ainsi). Les praticiens utilisent des expressions telles que « phase d'analyse », « analyse prédictive », « codage prédictif » ou « phase d'analyse » pour le processus qu'ils appliquent pour regrouper la masse de documents dans un ensemble pertinent de documents de grande valeur. Il comprend généralement :
Classification : Les utilisateurs rassemblent un ensemble représentatif sélectionné de documents à partir de la masse de documents existante qui représente les intérêts clés et la pertinence des sujets à analyser.
Mise en cluster : Ils élaborent des documents sélectionnés à l'étape de classification pour trouver des documents similaires qui correspondent aux définitions de cluster requises et aux algorithmes des documents représentatifs.
Résumé : Cette organisation aide l'utilisateur à sélectionner des sections clés de ces documents sous forme de mots clés, de phrases et de résumés à utiliser dans des applications de gestion des litiges ou de gouvernance d'entreprise.
N-grammes : Les N-grammes sont la cooccurrence de base de plusieurs mots qui se trouvent dans n'importe quel contexte. Ils pourraient aider à identifier un ensemble de documents qui ont plus de pertinence et de valeur dans des enquêtes et des examens spécifiques et qui sont utiles dans le processus de vannage, ou pour comprendre le profil linguistique de la masse de documents
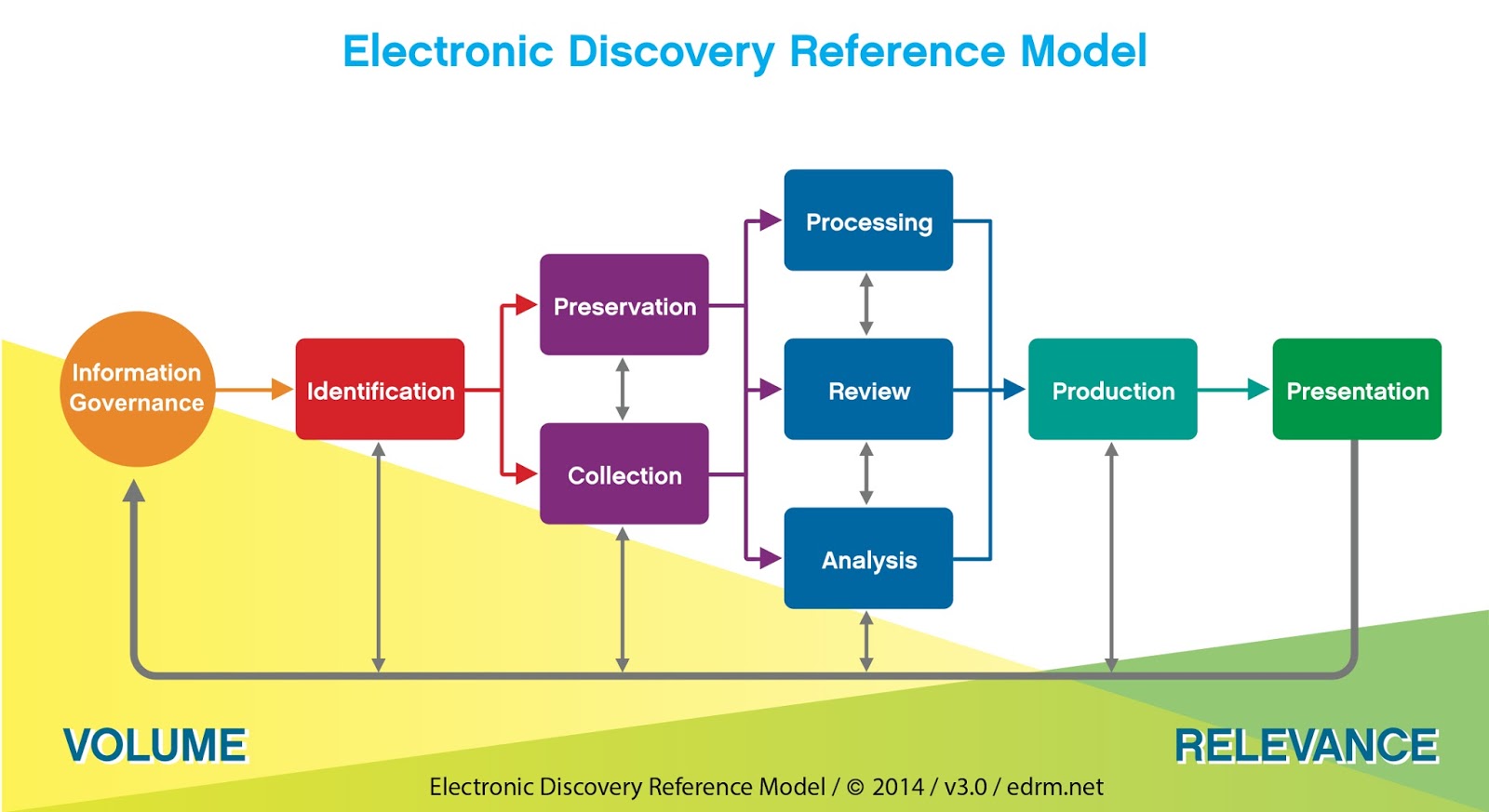
Le modèle EDRM passe en revue le cheminement typique du processus vers une pertinence accrue
Ainsi, après l'organisation, les documents de classement et d'identification sont envoyés à un processus de traduction qui nécessitera souvent MT en raison du volume. MT permet d'identifier les bons documents pour les affiner (avec une traduction humaine) ou les analyser et les réviser. Cette identification d'un petit ensemble de documents plus importants à partir d'un grand ensemble est l'essence du processus de triage.
Nos projets sont variés et ne sont pas tous axés sur les litiges. Par exemple, nous effectuons souvent des exercices de réglementation et des enquêtes. Dans ces situations, on ne sait souvent pas au départ ce qui est nécessaire ; par conséquent, l'élimination des données est davantage fondée sur une enquête nous [ ... ]état d'esprit d'investigation] et l'utilisation de fonctions analytiques telles que la catégorisation ou le clustering de documents. Dans ce cas, des échantillons de divers documents, liés à différentes routes d'enquête, sont envoyés pour traduction à [MT pour] aider nos équipes à développer une compréhension des données. La capacité de donner à nos enquêteurs la possibilité de traduire des documents à la volée est également un avantage énorme dans ce genre de dossiers. Alvarez & Marsal, Royaume-Uni
En ce qui concerne les langues qui comptent dans l'eDiscovery, l'impression que j'ai tirée de mon enquête est qu'elle est assez diversifiée, mais une grande partie du travail consiste à passer d'une variété de langues sources à l'anglais (ou à l'allemand). Certains disent que CJK et Figues sont les plus importants dans un monde de plus en plus global, mais les besoins sont toujours spécifiques au cas par cas, de sorte qu'ils peuvent aller jusqu'à la Grèce, la Norvège et la Suède. En ce qui concerne les domaines d'intérêt, nous constatons que dans les scénarios de litige, la responsabilité du fait des produits et la contrefaçon des brevets ont tendance à dominer, mais ces catégories pourraient couvrir un large éventail de domaines allant de l'électronique grand public, des TI, de l'automobile, des produits pharmaceutiques/de l'équipement médical, aux industries financières et extractives.
Bien que de nombreux projets d'e-discovery ne soient assimilés qu'au contenu lié aux litiges, le marché au-delà des litiges semble croître tout aussi rapidement. Dans un monde de plus en plus numérique, la nécessité de comprendre les flux de données électroniques au sein d'une entreprise mondiale pour les besoins de gouvernance de l'information peut être utile pour de nombreuses raisons différentes, comme A & M le souligne encore :
« Alvarez & Marsal reçoivent des instructions sur un très large éventail de sujets, y compris les projets litigieux concernant les enquêtes internes, le règlement des litiges, l’insolvabilité et les programmes de conformité. Cependant, tous ne sont pas de nature litigieuse – par exemple, l'amélioration de la performance et les évaluations. Un fil conducteur est qu'ils sont « lourds » en matière de documents et qu'ils nécessitent donc nos compétences pour les mener efficacement. L'utilisation de la technologie diffère dans chaque scénario. Par conséquent, la compréhension des exigences du client et des capacités de la technologie nous permet de concevoir des flux de travail appropriés pour la gestion des documents. Cependant, lorsque des langues étrangères sont impliquées, nous utilisons les technologies de traduction Systran pour le même effet. »

L'eDiscovery est essentiellement un processus d'élimination des données et de classement de la pertinence
Quels sont les éléments importants d'une solution MT pour l'e-discovery ?
Accessibilité rapide et simple :
Les avocats, les professionnels de la gouvernance d'entreprise et de la conformité qui travaillent à partir d'un environnement de plate-forme eDiscovery doivent être en mesure d'exploiter MT avec facilité. Et le plus souvent, cela se fera directement à partir de la plate-forme d'analyse et d'organisation de documents qui est l'application clé pour beaucoup de ces professionnels. Cependant, dans de très grands cas, les documents peuvent être envoyés en vrac à MT, mais là encore, la capacité de gérer et d'examiner les documents pertinents à partir de la plate-forme d'examen est une exigence clé.
Identification linguistique :
L'une des premières étapes de la classification et de l'organisation des documents consiste à regrouper les documents par langue source. Il s'agit donc d'une étape critique du processus. La facilité et l'efficacité de ce processus d'identification de la langue sont très importantes pour de nombreux utilisateurs, car il s'agit du premier niveau de triage. En outre, certaines langues peuvent nécessiter des flux de traitement différents si MT n'est pas disponible et que des procédures non automatisées doivent être intégrées. La capacité d'identifier automatiquement la langue source à la volée pour une grande variété de langues est également une exigence clé, car les réviseurs suivent les fils de pertinence et ont besoin de traductions ad hoc des documents à la volée qui sont liés à l'objet de l'enquête. Souvent, les réviseurs soumettent un lot de documents qui peuvent être dans différentes langues, donc une solution MT qui peut identifier et traduire automatiquement est un avantage, et permet de télécharger des lots de fichiers sans se soucier de la langue dans laquelle ils sont.
Intégration à la plateforme eDiscovery :
Cela doit être beaucoup plus profond que de pouvoir passer des fichiers texte source et cible d'un côté et de l'autre. Relativité est une plate-forme de révision de documents particulièrement importante dans l'e-discovery, en particulier dans les scénarios de litige. Ils ont également été largement utilisés comme plate-forme d'examen de choix par beaucoup de ceux qui se soucient du traitement du contenu multilingue. L'une des raisons pour lesquelles SYSTRAN domine dans le segment eDiscovery est qu'ils ont une natif Connecteur Relativité. Il s'agit d'une intégration « profonde » conçue pour s'intégrer de manière transparente dans l'interface logicielle déjà familière aux utilisateurs de Relativité. Elle est conçue en tenant compte des meilleures pratiques en matière de Relativité et validée par Relativité et ses clients existants afin d'offrir une valeur ajoutée dans des cas de découverte multilingue réels. L'intégration profonde avec cette plate-forme permet non seulement l'identification et la traduction dans une seule langue, mais également plusieurs identifications et traductions dans un seul document, ce qui est particulièrement important pour les threads de messagerie. J'ai remarqué pendant de nombreuses années dans le secteur des MT que l'intégration avec une plate-forme de révision de documents est une exigence particulièrement importante, et bien que Relativité ne soit pas la seule plate-forme eDiscovery disponible, elle est probablement la plus importante. Voici un Magic Quadrant de Gartner pour le logiciel eDiscovery où vous pouvez voir que kCura (Relativité) est un leader.
Possibilité de traiter les formats de document principal :
Il s'agirait au minimum d'e-mails, de documents Office, de fichiers texte, de fichiers PDF, de contenu Web et, de plus en plus, de contenu des médias sociaux de Twitter et Facebook, ainsi que de contenu audio et vidéo. De plus en plus, nous constatons que les courriels sont le format de document le plus courant qui est traité dans une plateforme d'examen. Souvent, un fil de discussion d'e-mail peut être en deux langues ou plus et le besoin du marché pour des solutions MT qui peuvent gérer plusieurs langues dans le même document est devenu beaucoup plus urgent et même une exigence obligatoire.
Sécurité et confidentialité des données :
Pour certaines questions, les utilisateurs tiennent à ce que les systèmes puissent être installés sur place et qu'aucune donnée ne soit transportée en dehors d'un pare-feu sécurisé. Il existe souvent des restrictions de conservation des données liées aux projets qui limitent également considérablement les solutions MT pouvant être utilisées.
Évolutivité – Capacité de traiter des ensembles de données très volumineux en plus des besoins ad hoc :
Dans certains cas, des téraoctets, voire des pétaoctets de données peuvent être nécessaires. Dans de tels cas, l'efficacité de MT peut être un facteur important et conduire la sélection du système MT. Sur ces très grands projets de taille PB, les solutions RBMT ont un net avantage (en termes de performance et d'efficacité de traitement brute) et cela explique peut-être aussi pourquoi SYSTRAN a été un acteur dominant sur ce segment de marché à long terme. Ils peuvent fournir une gamme de solutions MT qui peuvent répondre aux différentes exigences des utilisateurs. Le degré d'automatisation devrait être tel que 10 000 documents puissent être soumis avec la même facilité que 10 documents.
Facilement personnalisable :
La personnalisation des systèmes MT peut varier en termes de complexité et d'investissement en temps. Cela peut être fait rapidement avec des dictionnaires et des glossaires, ou dans certains cas, certains fournisseurs fournissent des bases de référence pré-construites axées sur le domaine des moteurs MT, par exemple automobile, financier, chimique, informatique, juridique. Pour les cas/sujets à valeur élevée et de très longue durée, la personnalisation basée sur la mémoire de traduction peut s'avérer nécessaire, mais le scénario le plus courant dans eDiscovery semble être la personnalisation rapide. La disponibilité d'une gamme de glossaires de domaine et de moteurs axés sur le domaine permet d'obtenir des résultats MT de meilleure qualité avec un minimum d'effort. Le marché semble avoir besoin d'une interface Web simple, par pointer-cliquer, permettant d'ajouter des termes de dictionnaire ou des mémoires de traduction (TM), pouvant inclure des fonctionnalités de test et de déploiement intégrées, ainsi que des MT spécifiques au domaine prêts à l'emploi pour une variété de domaines, comme décrit ci-dessus. En outre, un flux typique peut impliquer qu'une personnalisation limitée est effectuée au niveau du volume, mais une fois qu'un jeu de documents est éliminé, il est logique de personnaliser le système MT pour améliorer la qualité de sortie MT. La qualité de sortie MT est un déterminant important de la sélection, comme nous le voyons dans le commentaire de l'utilisateur ci-dessous. Un processus de personnalisation efficace permet également d'extraire l'ensemble de documents le plus pertinent pour les efforts de traduction humaine.
Fonctionnalités spéciales:
Les fournisseurs de MT peuvent faire plusieurs choses pour aider les utilisateurs à obtenir de meilleurs résultats de sortie, et certains fournisseurs proposent des moyens d'effectuer une personnalisation rapide avec des glossaires qui sont pilotés par l'analyse n-gramme, utilisent des données monolingues pour améliorer la fluidité et intègrent rapidement les TM disponibles pour régler le moteur sur le sujet d'intérêt. SYSTRAN étant présent sur ce marché depuis plus longtemps que d'autres, ils disposent également d'une gamme d'outils spéciaux qui comprennent :
- Certains systèmes permettent anonymisation et/ou l'utilisation d'un pseudonyme pour les données d'examen afin de permettre et de faciliter les transferts et les examens de données transfrontaliers. Cela permet le partage des données entre les groupes de travail, tout en respectant les lois internationales sur la confidentialité des données et les exigences légales en matière de chaîne de possession.
- Pour les utilisateurs avancés et plus techniques, il existe également des fournisseurs qui fournissent des kits d'outils à faire analyse et modification du corps. Cela permettrait aux utilisateurs d'ajouter des routines linguistiquement informées pour améliorer les données au-delà de ce que la plateforme eDiscovery peut faire.
- Audio et vidéo. La nécessité de pouvoir gérer les documents numériques inclut désormais de plus en plus les messages vocaux, les enregistrements de conférences téléphoniques et les vidéos.
Bien que je ne suggère pas que SYSTRAN est le seul fournisseur de MT qui pourrait répondre aux besoins de MT sur le marché de l'e-discovery, je dis qu'ils ont résolu plusieurs problèmes très spécifiques qui vraiment important pour un utilisateur eDiscovery, et sont donc susceptibles d'être un fournisseur privilégié dans de nombreux cas liés à l'eDiscovery multilingue, de la même manière que la relativité est pour les applications eDiscovery en général. Pour soutenir Alvarez & Marsal, commente :
« L’une des principales raisons d’utiliser SYSTRAN était la profondeur de l'intégration avec la relativité, ce qui signifie que nos clients considèrent qu'il s'agit d'une solution connectée, flexible et efficace – leur apportant réassurance et confort en n'ayant qu'un seul outil à utiliser [Relativité]. En outre, la rapidité et la précision des traductions ont été impressionnants lorsqu'ils ont été comparés à d'autres fournisseurs, ainsi que la simplicité de la traduction précise des documents en quelques clics de souris.
Les perspectives pour l'avenir suggèrent que l'e-discovery ne fera que prendre de l'ampleur au fur et à mesure que la gouvernance d'entreprise commencera à surveiller les médias sociaux, et que nous réaliserons que le courrier électronique est de plus en plus considéré comme une source de problèmes pour les questions de gouvernance de l'information et de conformité. Réglementation émergente, en particulier en Europe, suggèrent que le besoin sera encore plus grand dans l'UE. Plusieurs fournisseurs de services d'e-discovery à qui j'ai parlé m'ont laissé entendre que les documents multilingues sont de plus en plus courants et que cette tendance ne fera que prendre de l'ampleur à l'avenir.
Un dernier commentaire de A&M :
Le besoin de traductions précises et efficaces est certainement en augmentation sur le marché de l’eDiscovery… Nous consultons de plus en plus de clients dont les données contiennent un mélange de différentes langues et nous ne voyons pas ce besoin ralentir dans un avenir proche. »
[Source]




