
This article originally appeared on Kirti Vashee’s Blog.
There are some kinds of translation applications where MT just makes sense, and it would be foolish to even attempt these kinds of projects without decent MT technology as a foundation. Usually, this is because these applications have some combination of the following factors:
- Very large volume of source content that simply could NOT be translated without MT in any useful time frame
- Rapid turnaround requirement (days, hours or minutes) for the content to have any value to the translation consumers
- A user tolerance for lower quality translations at least in early stages of information review
- To enable information and document triage when dealing with large document collections and help to identify highest priority content from a large mass of undifferentiated content. This process also helps to identify the most important and relevant documents to send to higher quality human translation.
- Translation Cost prohibitions (usually related to volume)
One can find this combination of requirements in several customer communications oriented applications like technical support knowledge-base, eCommerce product listings, customer service, and CX reviews for all kinds of products and service experiences. However, in an increasingly digital world, we see the need to be able to process large volumes of business content to identify what is most relevant and valuable for ongoing business mission needs as well. One such business information triage application is eDiscovery. In my time in working with MT, I have seen that this is an ongoing need that will continue to build momentum as we become digitally focused workers.
SYSTRAN has been a leader amongst MT solution providers in the eDiscovery segment, and have a long track record of success in this segment, and from my vantage point, a greater sensitivity to the customer needs of this segment than most others. Recently, they gave me unhindered access to a few of their eDiscovery customers, who provided insight into what really matters in terms of MT from the user perspective. This post will describe some key requirements from an active user’s perspective, especially Alvarez & Marsal in London. In particular, their willingness to share their insights enabled me to provide and validate my own observations made in the substance of this post. I have also had a previous guest post from iQwest that also described the use of MT in eDiscovery applications from a service provider perspective.

What is eDiscovery?
Electronic discovery (sometimes known as e-discovery, eDiscovery, or e-Discovery) is the electronic aspect of identifying, collecting and producing electronically stored information (ESI) in response to a request for production in a lawsuit or internal corporate investigation. ESI includes, but is not limited to, emails, documents, presentations, databases, voicemail, audio and video files, social media content, and websites.
The processes and technologies around eDiscovery are often complex because of the sheer volume/variety of electronic data produced and stored. Additionally, unlike hard-copy evidence, electronic documents are more dynamic and often contain metadata such as time-date stamps, author and recipient information, and file properties. Preserving the original content and metadata for electronically stored information is required in order to eliminate claims of spoliation or tampering with evidence later in a litigation scenario.
What typically happens with an initially large mass of documents in an eDiscovery scenario is that some combination of the following activities is run to help organize and identify the most important material from a large document mass (Not sure it is quite a corpus – usually it is much too unstructured to call it that). Practitioners use phrases like “analytics phase”, “predictive analytics”, “predictive coding”, or “analysis phase” to the process they apply to winnow the document mass into a relevant set of high-value documents. It usually includes:
Classification: Users gather a select representative set of the documents from the existing document mass that represents the key interests and relevance of subject matters to be analyzed.
Clustering: They build out documents selected in the classification stage to find similar documents that match required cluster definitions and algorithms of the representative documents.
Summarization: This organization assists the user in selecting key sections of these documents as keywords, phrases, and summaries for use in litigation or corporate governance applications.
N-Grams: N-Grams are the basic co-occurrence of multiple words that are within any context. These could help identify a set of documents that have higher relevance and value in specific investigations and review and be useful in the winnowing process, or in understanding the linguistic profile of the mass of documents
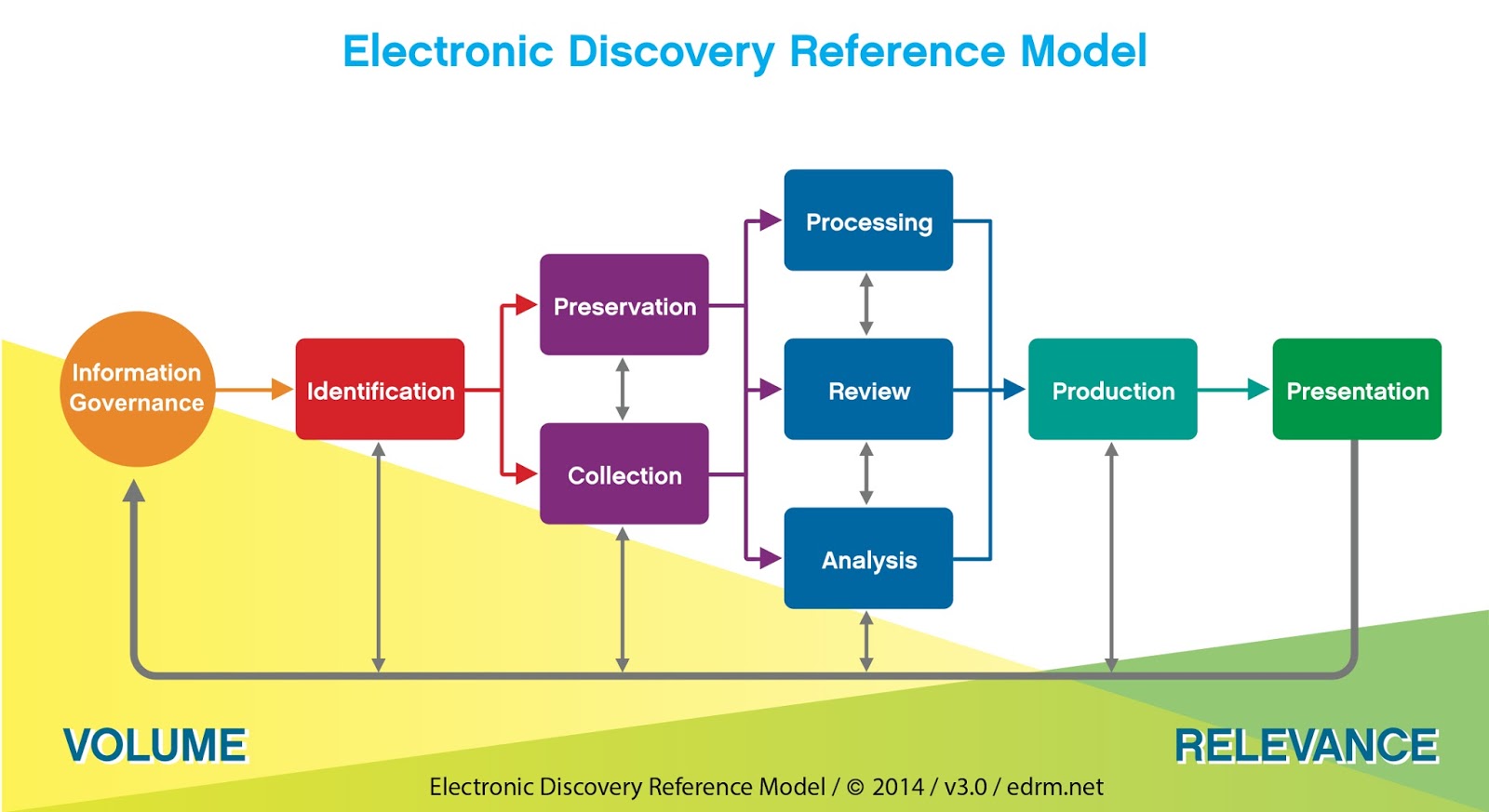
The EDRM model overviews the typical process journey to increased relevance
Thus, after organization, collation and identification documents are sent to a translation process which will often require MT because of the sheer volume. MT allows the right documents to be identified for further refinement (with human translation) or analysis and review. This identification of a smaller set of more important documents from a large set is the essence of the triage process.
Our projects are varied and are not all focused around litigation. For example we often perform regulatory exercises and investigations. In these situations, it is often not known at the onset what is required; therefore, the culling of data is based more upon an investigative nous [investigative mindset] and the utilization of analytics features such as document categorization or clustering. In this instance, samples of various documents, related to different investigatory routes, are sent for translation to [MT to] help our teams develop an understanding of the data. The ability to provide our investigators with the option to translate documents on the fly is also a massive benefit in these types of matters.” Alvarez & Marsal, UK
In terms of languages that matter in eDiscovery, the sense I get from my investigation is that it is quite diverse, but a lot of the work involves going from a variety of source languages into English (or German). Some say that CJK and FIGS matter most in an increasingly global world, but the needs are always case-specific so it can be as far ranging as Greek, Norwegian, and Swedish. In terms of subject domains of focus, we see that in the litigation scenarios, product liability, and patent infringement tend to dominate, but these categories could cover a wide range of domains ranging from consumer electronics, IT, automotive, pharmaceuticals/medical equipment, to financial and also extractive industries.
While many equate eDiscovery projects only with litigation related content, the market beyond litigation seems to be growing just as rapidly. In an increasingly digital world, the need to understand electronic data flows within a global enterprise for information governance needs can be useful for many different reasons as A & M again point out:
“Alvarez & Marsal get instructed on a very wide range of matters, including contentious projects around internal investigations, dispute resolution, insolvency, and compliance programs. However, not all of them are contentious in nature – for example, performance improvement and valuations. A common thread is that they are document ‘heavy’ and therefore require our skill sets to effectively conduct them. The use of the technology differs in each scenario. As a result, understanding the client requirements and the capabilities of the technology allows us to devise suitable workflows for handling the documents. However, where foreign languages are involved we use Systran translation technologies to the same effect. “

eDiscovery is basically a data culling and relevance ranking process
What Matters in an MT Solution for eDiscovery?
Rapid and Straightforward Accessibility:
Attorneys, corporate governance and compliance professionals who function from within an eDiscovery platform environment need to be able to operate MT with ease. And most typically this will be from directly within the document analysis and organization platform that is the key application for many of these professionals. However, in very large cases documents may be sent in bulk to MT, but again the ability to manage and review relevant documents from within the review platform is a key requirement.
Language Identification:
One of the first steps in classification and organization of documents is to group documents by source language and thus this is a critical step in the process. The ease and efficiency of this language identification process is very important for many users, as it is the first level of triage. Also, some languages may need different processing flows if MT is not available and non-automated procedures need to be incorporated. The ability to automatically identify the source language on-the-fly for a large variety of languages is also a key requirement, as reviewers follow relevance threads and need ad-hoc translations of documents on-the-fly that are related to investigation subject matter. Often reviewers will submit a batch of documents that may be in different languages, thus an MT solution that can automatically identify and translate is an advantage, and allows batches of files to be uploaded without concern regarding what language they are in.
Integration with the eDiscovery Platform:
This needs to be much deeper than being able to pass source and target text files back and forth. Relativity is a particularly important document review platform in eDiscovery, especially in litigation scenarios. They also have been used extensively as the review platform of choice by many who care about processing multilingual content. One reason that SYSTRAN dominates in the eDiscovery segment is that they have a native Relativity connector. This is a “deep integration” that is built to integrate seamlessly into the software interface already familiar to Relativity users, and is built with Relativity best practices in mind, and validated by Relativity and their existing customers to provide value in real-world multilingual discovery cases. The deep integration with this platform not only allows single language identification and translation but also allows for multiple language identifications and translation within a single document, which is especially important for email threads. I have noticed over many years in the MT business that integration with a document review platform is a particularly important requirement, and while Relativity is not the only eDiscovery platform available, it is probably the most important one. Here is a Gartner Magic Quadrant for eDiscovery software where you can see that kCura (Relativity) is a leader.
Ability to Process Primary Document Formats:
This would at a minimum be emails, Office documents, text files, PDFs, web content, and increasingly social media content from Twitter and Facebook, as well as audio and video content. More and more, we see that emails are the most common document format that is processed in a review platform. Often an email thread could be in two or more languages and thus the market need for MT solutions that can handle multiple languages within the same document has become much more urgent and even a mandatory requirement.
Security and Data Privacy:
For some matters, users care that systems can be installed on-premise and that no data is transported outside a secure firewall. There are often data custody restrictions linked to projects which also greatly constrain what MT solutions can be used.
Scalability – Ability to process Very Large Data Sets in addition to Ad-Hoc needs:
Some cases may require that terabytes and even petabytes of data are involved. In such cases, MT efficiency can be a significant factor and drive MT system selection. On these very large PB sized projects, RBMT solutions have a clear advantage (in terms of performance and raw processing efficiency) and this perhaps also explains why SYSTRAN has been a long-term and dominant player in this market segment. They can provide a range of MT solutions that can meet different user requirements. The degree of automation should be such that 10,000 documents can be submitted with the same ease as 10 documents can.
Easily Customizable:
Customization of MT systems can vary in complexity and time investment requirements. It can be done rapidly with dictionaries and glossaries, or in some cases some vendors provide pre-built domain focused baselines MT engines e.g. automotive, financial, chemical, IT, legal. For very long-running and high-value cases/subject matter the need may arise for translation memory based customization, but the most common scenario in eDiscovery seems to be rapid customization. The availability of a range of domain glossaries and domain focused engines make higher quality MT output possibly with minimum effort. There seems to a market need for a web-based simple point-and-click interface for adding dictionary terms or translation memories (TMs), that can include integrated testing and deployment features, and also out-of-the-box domain-specific MT for a variety of domains as described above. Also, a typical flow may involve that limited customization is done on the bulk level but once a document set is culled, it makes sense to customize the MT system to improve MT output quality. MT output quality is an important determinant of selection, as we see from the user comment below. An effective customization process also helps to extract the most relevant set of documents for human translation efforts.
Special Features:
There are several things that MT vendors can do to help users get better output results, and some vendors provide ways to perform rapid customization with glossaries that are driven by n-gram analysis, use monolingual data to improve fluency and quickly incorporate available TM to tune the engine on the subject matter of interest. As SYSTRAN has been in this market longer than others, they also have a range of special tools which include:
- Some systems allow for anonymization and/or pseudonym-enabling of review data to enable and facilitate cross-border data transfers & reviews. This allows data sharing between work groups, while still complying with international data privacy laws and legal chain of custody requirements.
- For advanced and more technical users there are also some vendors who provide toolkits to do corpus analysis and modification. This would allow users to add linguistically informed routines to enhance the data above and beyond what the eDiscovery platform can do.
- Audio & Video. The need to be able to handle digital “documents” now increasingly includes voicemails, conference call recordings and video.
While I am not suggesting that SYSTRAN is the only MT vendor who could service eDiscovery market MT needs, I am saying that they have solved several very specific problems that really matter to an eDiscovery user, and thus are likely to be a preferred vendor in many cases related to multilingual eDiscovery, in the same way that Relativity is for eDiscovery applications in general. In support Alvarez & Marsal comments:
“A key reason for using SYSTRAN was the depth of integration with Relativity, which means our clients see it is as one connected, flexible and effective solution – providing them with reassurance and comfort in only having to use one tool [Relativity]. In addition, the speed and accuracy of the translations were impressive when benchmarked against other providers, as well as the simplicity of accurately translating documents with a few mouse clicks.
The outlook for the future suggests that the eDiscovery will only gain momentum as corporate governance begins to monitor social media, and as we realize that email is increasingly understood to be a source of problems for information governance issues and compliance. Emerging regulations, especially in Europe, suggest the need will be even greater in the EU. Several eDiscovery service providers I talk to have suggested that multilingual documents are now increasingly common and this trend will only gain momentum in future.
A closing comment from A&M:
The need for accurate and efficient translations is definitely growing within the eDiscovery market… We are consulting more and more with clients whose data contains a mix of various languages and we do not see this need slowing down in the near future. “
[Source]




