
The pandemic has highlighted the rise of globalization and just how interconnected the world economy truly is. Companies and organizations that are looking to thrive in today’s economy are required to have a global footprint and serve millions of employees and customers worldwide. Organizations with global operations cannot simply export their country of origin’s culture and practices to their international customers. The many differences in culture, language, and more will prevent these companies from succeeding. Companies should have a localization strategy to ensure their products and services translate well and avoid translation mistakes that can damage branding.
A good example of this is HSBC Bank. When HSBC Bank launched a branding campaign in Germany, they made a translation error that cost them over $10 million. The issue occurred when their tagline “Assume nothing” was mistakenly translated to “Do nothing” in German. This decreased confidence in the bank tremendously and HSBC Bank had to go through a total rebrand to gain back consumer confidence.

In other languages, it’s accepted that modifying the global environment is something to be done rarely, if ever. This instance highlights that companies need to think about robust language translation and localization so the global market can fully enjoy their products and services in their native tongues. Since global companies have products and services in many niches, they need to ensure that the language content on their sites can be both specific and specialized. Many companies already use manual language tools and translators to get this done. This adds significant overhead and higher translation costs and delays in translating materials.
A scalable and cost-effective solution is to use machine translation layers for their content. Translation machines can adapt to the dialect and language of each market that a company operates. With SYSTRAN’s Neural Machine Translation (NMT) tools, companies can work with our developers and linguists to build an engine that is fully specialized to specific language needs.
Training a translation engine is a multi-step, yet straightforward process. In this article, we will discuss the various steps required to train a translation engine for your business needs.
1. Define a Use Case
Before beginning, think about what exactly you need translated. What is the use case for the translation engine? Will the translation be product-specific or general translation for an entire site?
Product-specific translation will require more preparation and training in comparison to general translation such as billing information and HR contracts.

Are you intending to translate legal and contractual documents to facilitate international, cross-cultural coordination within your business? This use case requires a very different type of specialization than translating generic content like web pages or blogs.
Before beginning down the NMT training journey, have a clear idea of what exactly you will be translating as that will dictate the rest of the preparation process.
2. What Level of Quality is Needed?
After you understand what type(s) of content needs to be translated, it helps to understand how specific the translations need to be. For most use cases, generalized translations should fit the bill. For specific use cases that require translating technical work, specialized translations will be required. Some use cases will require highly specific, precise, and exact translations, perhaps with machine translation post editing. Relying on generalized engines for use cases like this will likely return unreliable and heavily erred translations that human oversight teams will have to review and correct. This will add more costs and added time for employees.
A clear set of goals and expectations regarding the level of accuracy and quality of localization will help our SYSTRAN team to understand what specific steps and processes need to be taken to fit your needs.
Based on your quality goals and needs, we can determine whether you simply need document translation or more detailed processes such as user dictionaries, tagging, and translation glossaries.
3. Collect and Assess Translation Memory
Once you understand the use cases and quality level that you need the translation engine to work at, the next step is gathering what we call “translation memory.” This is translated content with which we will be training the engine—the kindling that will ignite the fire. These usually come in the form of full sentences or phrases, but the former is preferred.
Typically, translation memory can be collected in two ways:
First, and the most effective, is through collecting all past translated material and loading it into the system. By doing this, you wouldn’t have to re-train the engines for the unique jargon. This huge advantage will allow the NMT to translate the new game with much greater accuracy and save your team hours of loading the engine’s Terminology Dictionaries with the same information over again.
However, what happens if a client does not hav
e any source material at all? In those situations, our team will research and procure suitable material that matches the content type you need. Whether it is through scouring the internet or using a linguist that specializes in the type of content your company produces, we can produce data that our NMTs can train on. Bear in mind that this can a
dd several weeks or even months to the onboarding process. Things are always faster and more efficient if the client has properly formatted training material on hand.
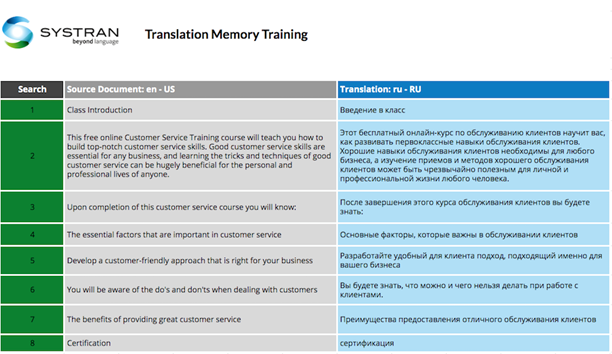
The ideal data format to train our translation engines would be a spreadsheet with full sentences in one column and that same translated sentence in a second column right next to it. For example, if you want to translate English content into Russian, the translation memory needs to have English sentences in one column and their Russian translations in a second column right next to their English equivalents.Most clients who already have some translated material on hand do not have it formatted for efficient engine training. Instead, they might have multiple copies of a document in different languages. While translations on a document level are better than nothing, it needs to be sorted and aligned sentence per sentence with the translations right next to each other before it can be used to train a translation engine.
Think of it like a person who is trying to learn a new language. They don’t learn an entire book’s worth of vocabulary at one time—reading a book in their own language cover to cover and then reading it again in the new language. They break it up into words and phrases—one word in their mother tongue, then again in the new language.
Computers, of course, are more efficient and can take whole sentences at a time instead of individual words. However, even NMT engines have processing limits. Entire documents may be too cumbersome and single words or phrases too simple, full sentences are the sweet spot that we use to train our NMT.
When we receive source material that is not aligned in a sentence-by-sentence structure, it takes additional time to re-format the material to be suitable for training. By ensuring that the source information that will be used to train with is formatted before sending it to us, you will be saving both time and money.
4. Tagging
At SYSTRAN, we understand that many companies utilize storytelling. To make a good story, you need characters with individual personalities — to include specific word choice and speech patterns. A company may use personas or personalities to mimic the behavior of their targeted user base. This is where “add on terminology” comes in. There might be a dozen different ways to say the same sentence or convey the same idea and those differences are what make storytelling unique for companies.
Add-on terminologies are specific words or phrases that we can train the engine to use within certain contexts. If the NMT comes across a specific sentence that could accurately be translated five different ways, it can use the add-on terminology to choose one translation that best fits the scenario.

For example, an executive covering a business briefing may use different terminology in comparison to a reporter or intern — even if their overall dialogue is essentially the same on the surface. Add on terminology, or tagging, is how our NMT captures the personal idiosyncrasies and nuances of word choice that bring personalities to life.
After compiling the foundational training data and formatting it sentence by sentence, providing our developers and linguists with add on terminology will go a long way towards ensuring the highest quality translations that preserve the spirit of your content.
5. Prepare for Training
Now that all the source material has been collected, the next step is to prepare for training. This includes cleaning up the contents, making sure they are formatted correctly, and verifying that they’re translated in the most desirable way. This step also includes scanning for spelling variations and typos so that the NMT is not stumped by non-standard spelling.
If the client has any user dictionaries, these can be added to the training material as well. Often, the bulk of the work for inputting terminology will come from the translation memories. There are a number of things the software can learn from extra terminology training.
6. Generic Training First
To keep the process as efficient as possible, we start all clients off with a generic engine. Generic engines are in themselves powerful translation systems that are fully capable of translating 99 percent of companies’ content. However, to fully realize the benefits of NMT for gaming, the engines have to be able to do work on specific content types as well.
From day one, the generalized engine begins ingesting the more specific training material provided by the client. That source material (translation memories), the add-on terminology, and user dictionaries can be added to the generic training until you hit the target goal of 40,000-50,000 segments of information. That is the desired number of added information that can be used to specialize the NMT to your needs, although additional segments may be required for further specialization, such as with medical and healthcare applications.
Even with this progress, learning never stops. After the initial 40,000-50,000 segments have been reached, the NMT should be receiving regular updates to the information so it can continue to refine its training and translations. New user dictionaries, new translation memory, and more terminology will continue to enhance the NMT so it can, over time be fully adapted, optimized, and customized to your specific domain and content.

How Long From Start to Finish?
Full specialization of an NMT to fit your specific needs can be as quick as a few days to as long as a month. One major factor in the timeline is how long it takes to gather and properly format the translation memory and data that will be used to initially specialize the NMT.
When all the input data is available and cleaned up, the actual training process is very efficient. It may take several hours to a day for an NMT to process 40,000-50,000 segments, but training is an iterative process. That means the NMT will be trained 30-40 times on those segments before it is ready for production.
Additionally, our NMT can be trained in multiple languages in parallel. So, if you need the engine to be capable of translating six or seven languages, you are not stuck waiting half a year for humans to do the work. SYSTRAN can train the NMT on groups of languages at a time, cutting down the timeline significantly.
Why SYSTRAN?
There are a variety of NMT services out there, so why choose SYSTRAN for your translation needs?
Scalability
We are the only company in the industry that provides fully scalable solutions for everyone from single users to global enterprises—and we provide it in multiple formats to fit your specific needs.
Secure Hosting Environments
One of the most popular formats for translation is cloud-based. It’s cost-effective and quick and easy to set up and host. Although SYSTRAN fully guarantees the security of our cloud-hosting, IP theft, and other security vulnerabilities that could risk the success of your company are serious factors we take into account when it comes to security. For that reason, we offer a robust on-premise solution that comprehensively protects your intellectual property.
Open Source Framework
Our NMT is based on the best open-source framework available with thousands of developers working on it daily. Then, we take our proprietary add-ons such as user dictionaries and custom techniques to enhance an already high-quality framework.
Due to the open framework, companies can not only see and understand what is happening under the hood, but they can also take an active part in developing it further and fine-tuning it. With SYSTRAN’s NMT, you can do more than simply translate content, you can fully understand, integrate, and build translation capabilities to suit your needs.




