
La pandémie a montré que le monde est de plus en plus connecté. Pour réussir aujourd'hui, les entreprises doivent être présentes à l'international et s'adresser à des millions d'employés et de clients partout dans le monde. Mais, ce n'est pas simplement une question de copier-coller de la culture et des habitudes de son pays d'origine aux clients étrangers. Les différences de culture, de langue, etc., compliquent les choses. C'est pourquoi les entreprises doivent avoir un process clair pour bien traduire leurs produits et services et ainsi éviter les erreurs de communication.
Un bon exemple de cela est la banque HSBC. Lorsque HSBC a lancé une campagne de branding en Allemagne, une erreur de traduction leur a coûté plus de 10 millions de dollars. Le problème est survenu lorsque leur slogan "Assume nothing" a été mal traduit par "Do nothing" en allemand. Cela a fortement diminué la confiance envers la banque, obligeant HSBC à revoir entièrement sa marque pour regagner la confiance des consommateurs.

Cet exemple met en évidence le fait que les entreprises doivent envisager une traduction et une localisation linguistique robustes afin que le marché mondial puisse pleinement profiter de leurs produits et services dans leur langue maternelle. Comme les entreprises mondiales proposent des produits et services dans de nombreuses niches, elles doivent veiller à ce que le contenu linguistique de leurs sites soit à la fois spécifique et spécialisé. De nombreuses entreprises ont déjà recours à des outils et des traducteurs manuels pour cela. Cela entraîne des coûts de traduction élevés, des charges supplémentaires importantes et des retards dans la traduction des documents.
Une solution évolutive et économique consiste à intégrer des outils de traduction automatique pour le contenu. Les systèmes de traduction automatique peuvent s'ajuster au dialecte et à la langue de chaque marché où une entreprise est présente. En utilisanttraduction automatique neuronale de SYSTRAN par exemple, les entreprises peuvent travailler avec nos développeurs et linguistes pour créer un moteur entièrement adapté à des besoins linguistiques spécifiques.
L'entraînement d'un moteur de traduction est un processus en plusieurs étapes, mais simple. Dans cet article, nous aborderons les différentes étapes nécessaires pour entraîner un moteur de traduction aux besoins de votre entreprise.
1. Définissez un cas d'usage
Avant de commencer, réfléchissez à ce que vous devez traduire. Quel est le cas d'usage du moteur de traduction ? La traduction sera-t-elle spécifique à un produit ou générale pour un site entier ?
La traduction spécifique à un produit nécessitera davantage de préparation et d'entraînement que la traduction générale, comme les informations de facturation et les contrats de ressources humaines.

Avez-vous l'intention de traduire des documents juridiques et contractuels pour faciliter la coordination internationale et interculturelle au sein de votre entreprise ? Ce cas d'usage nécessite un type de spécialisation très différent de la traduction de contenu générique comme des pages Web ou des blogs.
Avant de commencer un process de traduction neuronale, ayez une idée claire de ce que vous traduirez exactement, car cela dictera le reste du processus de préparation.
2. Quel est le niveau de qualité requis ?
Une fois que vous comprenez quel type de contenu doit être traduit, il est utile de comprendre à quel point les traductions doivent être spécifiques. Pour la plupart des cas d'utilisation, des traductions généralisées devraient suffire. Cependant, pour des cas d'utilisation spécifiques nécessitant la traduction de travaux techniques, des traductions spécialisées seront nécessaires. Certains cas d'utilisation nécessiteront des traductions hautement spécifiques, précises et exactes, peut-être avec une révision après traduction automatique. S'appuyer sur des moteurs généralisés pour des cas d'utilisation comme celui-ci risque de donner des traductions peu fiables et fortement erronées que des équipes de supervision humaine devront examiner et corriger. Cela ajoutera davantage de coûts et de temps pour les employés.
Un ensemble clair d'objectifs et d'attentes concernant le niveau de précision et de qualité de la localisation aidera notre équipe SYSTRAN à comprendre quelles étapes et processus spécifiques doivent être mis en œuvre pour répondre à vos besoins.
En fonction de vos objectifs et de vos besoins en matière de qualité, nous pouvons déterminer si vous avez simplement besoin d'une traduction de documents ou de processus plus détaillés tels que des dictionnaires utilisateur, des balises et des glossaires de traduction.
3. Collecter et évaluer la mémoire de traduction
Une fois que vous avez compris les cas d'utilisation et le niveau de qualité pour lesquels vous avez besoin du moteur de traduction, l'étape suivante consiste à rassembler ce que nous appelons la mémoire de traduction. C'est du contenu traduit avec lequel nous allons entraîner le moteur. Elles se présentent généralement sous la forme de phrases complètes ou de morceaux de phrases, mais la première option est préférable.
En général, la mémoire de traduction peut être collectée de deux manières :
La première, et la plus efficace, consiste à recueillir tous les documents traduits et à les télécharger dans le système de traduction automatique. En faisant cela, vous n'auriez pas à réentraîner les moteurs pour le jargon propre à votre secteur d'activité. Cet énorme avantage permettra à l'outil de traduction de traduire le nouveau jeu avec beaucoup plus de précision et d'économiser des heures à votre équipe.
Cependant, que se passe-t-il si un client n'a pas
Y a-t-il des sources ? Dans ces situations, notre équipe recherchera et se procurera du matériel adapté au type de contenu dont vous avez besoin. Que ce soit en parcourant Internet ou en utilisant un linguiste qui se spécialise dans le type de contenu que votre entreprise produit, nous pouvons produire des données sur lesquelles nos outils de gestion de contenu peuvent se former. A noter que cela peut
Ajoutez plusieurs semaines, voire plusieurs mois, au processus d'intégration. Les choses sont toujours plus rapides et plus efficaces si le client dispose de matériel de formation correctement formaté.
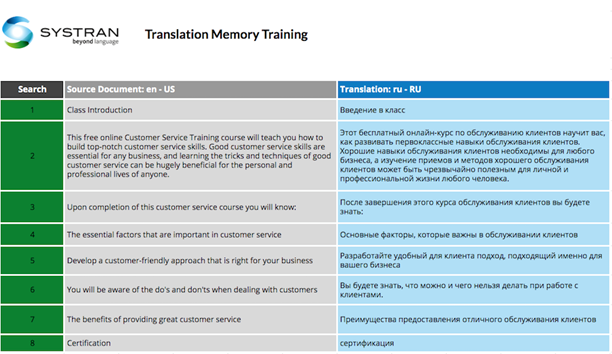
Le format de données idéal pour entraîner nos moteurs de traduction serait une feuille de calcul avec des phrases complètes dans une colonne et la même phrase traduite dans une deuxième colonne juste à côté. Par exemple, si vous voulez traduire du contenu en anglais en russe, la mémoire de traduction doit avoir des phrases en anglais dans une colonne et leurs traductions en russe dans une deuxième colonne juste à côté de leurs équivalents en anglais. La plupart des clients qui ont déjà du matériel traduit en main ne l'ont pas formaté pour une formation efficace sur les moteurs. Ils peuvent avoir plusieurs copies d'un document dans différentes langues. Bien que les traductions au niveau du document soient mieux que rien, elles doivent être triées et alignées phrase par phrase avec les traductions les unes à côté des autres avant de pouvoir être utilisées pour former un moteur de traduction.
Pensez-y comme une personne qui essaie d'apprendre une nouvelle langue. Ils n'apprennent pas le vocabulaire d'un livre en entier à la fois, en lisant un livre dans leur propre langue, de couverture en couverture, puis en le relisant dans la nouvelle langue. Ils le divisent en mots et en phrases ? un mot dans leur langue maternelle, puis à nouveau dans la nouvelle langue.
Les ordinateurs, bien sûr, sont plus efficaces et peuvent prendre des phrases entières à la fois au lieu de mots individuels. Cependant, même les moteurs NMT ont des limites de traitement. Des documents entiers peuvent être trop encombrants et des mots ou des phrases uniques trop simples, des phrases complètes sont le point idéal que nous utilisons pour former notre NMT.
Lorsque nous recevons du matériel de base qui n'est pas aligné dans une structure phrase par phrase, il faut plus de temps pour reformater le matériel afin qu'il soit adapté à la formation. En vous assurant que les informations sources qui seront utilisées pour la formation sont formatées avant de nous les envoyer, vous économiserez à la fois du temps et de l'argent.
4. Marquage
Chez SYSTRAN, nous comprenons que de nombreuses entreprises utilisent la narration. Pour faire une bonne histoire, vous avez besoin de personnages avec des personnalités individuelles ? pour inclure le choix de mots spécifiques et les modèles de parole. Une entreprise peut utiliser des personnages ou des personnalités pour imiter le comportement de sa base d'utilisateurs ciblée. C'est là que ?add on terminology ? entre en jeu. Il peut y avoir une douzaine de façons différentes de dire la même phrase ou de transmettre la même idée, et ces différences sont ce qui rend la narration unique pour les entreprises.
Les terminologies complémentaires sont des mots ou des expressions spécifiques que nous pouvons apprendre au moteur à utiliser dans certains contextes. Si l'outil NMT trouve une phrase spécifique qui pourrait être traduite exactement de cinq manières différentes, il peut utiliser la terminologie du module complémentaire pour choisir la traduction qui correspond le mieux au scénario.

Par exemple, un cadre dirigeant qui couvre une séance d'information commerciale peut utiliser une terminologie différente de celle d'un journaliste ou d'un stagiaire, même si leur dialogue global est essentiellement le même à première vue. Si l'on ajoute la terminologie, ou le balisage, c'est la façon dont notre NMT saisit les particularités et les nuances personnelles du choix des mots qui donnent vie aux personnalités.
Après avoir compilé les données de formation de base et les avoir mises en forme phrase par phrase, fournir à nos développeurs et linguistes une terminologie supplémentaire contribuera grandement à assurer des traductions de la plus haute qualité qui préservent l'esprit de votre contenu.
5. Préparez-vous à la formation
Maintenant que tout le matériel de base a été collecté, l'étape suivante consiste à se préparer à la formation. Cela comprend le nettoyage du contenu, s'assurer qu'il est correctement formaté et vérifier qu'il est traduit de la manière la plus souhaitable. Cette étape comprend également la recherche de variations d'orthographe et de fautes de frappe afin que le NMT ne soit pas interrompu par une orthographe non standard.
Si le client en a dictionnaires utilisateurCes derniers peuvent également être ajoutés au matériel de formation. Souvent, la plus grande partie du travail d'entrée de la terminologie provient des mémoires de traduction. Le logiciel peut apprendre un certain nombre de choses grâce à une formation terminologique supplémentaire.
6. Formation générique d'abord
Afin de maintenir le processus aussi efficace que possible, nous démarrons tous les clients avec un moteur générique. Les moteurs génériques sont en eux-mêmes de puissants systèmes de traduction qui sont pleinement capables de traduire 99 % du contenu des entreprises. Cependant, pour tirer pleinement parti des avantages de NMT pour les jeux, les moteurs doivent être en mesure de travailler sur des types de contenu spécifiques également.
Dès le premier jour, le moteur généralisé commence à ingérer le matériel de formation plus spécifique fourni par le client. Ces documents sources (mémoires de traduction), la terminologie complémentaire et les dictionnaires utilisateur peuvent être ajoutés à la formation générique jusqu'à ce que vous atteigniez l'objectif de 40 000 à 50 000 segments d'informations. Il s'agit du nombre souhaité d'informations supplémentaires qui peuvent être utilisées pour spécialiser l'outil NMT en fonction de vos besoins, bien que des segments supplémentaires puissent être nécessaires pour une spécialisation plus poussée, par exemple avec applications médicales et de santé.
Malgré ces progrès, l'apprentissage ne s'arrête jamais. Une fois que les 40 000 à 50 000 segments initiaux auront été atteints, l'équipe devrait recevoir des mises à jour régulières de l'information afin de pouvoir continuer à affiner sa formation et ses traductions. De nouveaux dictionnaires d'utilisateurs, de nouvelles mémoires de traduction et davantage de terminologie continueront d'améliorer le NMT afin qu'il puisse, au fil du temps, être entièrement adapté, optimisé et personnalisé à votre domaine et contenu spécifique.

Combien de temps du début à la fin ?
La spécialisation complète d'un outil NMT pour répondre à vos besoins spécifiques peut être aussi rapide que quelques jours à un mois. L'un des principaux facteurs de la chronologie est le temps nécessaire pour rassembler et formater correctement la mémoire de traduction et les données qui seront utilisées pour la spécialisation initiale de l'outil NMT.
Lorsque toutes les données d'entrée sont disponibles et nettoyées, le processus de formation réel est très efficace. Le traitement de 40 000 à 50 000 segments par un outil NMT peut prendre plusieurs heures à une journée, mais la formation est un processus itératif. Cela signifie que la NMT sera formée 30 à 40 fois sur ces segments avant d'être prête pour la production.
De plus, notre NMT peut être formé en plusieurs langues en parallèle. Donc, si vous avez besoin du moteur pour être capable de traduire six ou sept langues, vous n'êtes pas coincé à attendre six mois que les humains fassent le travail. SYSTRAN peut entraîner le NMT sur des groupes de langues à la fois, ce qui réduit considérablement le temps.
Pourquoi SYSTRAN ?
Il existe une variété de services NMT, alors pourquoi choisir SYSTRAN pour vos besoins de traduction ?
Flexibilité
Nous sommes la seule entreprise de l'industrie à fournir des solutions entièrement évolutives pour tous, des utilisateurs uniques aux entreprises mondiales, et nous les fournissons dans de multiples formats pour répondre à vos besoins spécifiques.
Environnements d'hébergement sécurisés
L'un des formats de traduction les plus populaires est le cloud. Il est économique, rapide et facile à configurer et à héberger. Bien que SYSTRAN garantisse entièrement la sécurité de notre hébergement cloud, le vol d'IP et d'autres vulnérabilités de sécurité qui pourraient mettre en péril le succès de votre entreprise sont des facteurs sérieux que nous prenons en compte quand il s'agit de sécurité. C'est pourquoi nous proposons une solution robuste sur site qui protège votre propriété intellectuelle de manière exhaustive.
Infrastructure Open Source
Notre NMT est basé sur le meilleur cadre open-source disponible avec des milliers de développeurs qui y travaillent quotidiennement. Ensuite, nous utilisons nos modules d'extension propriétaires tels que les dictionnaires utilisateur et les techniques personnalisées pour améliorer un cadre déjà de haute qualité.
Grâce au cadre ouvert, les entreprises peuvent non seulement voir et comprendre ce qui se passe sous le capot, mais elles peuvent également participer activement à son développement et à son ajustement. Avec SYSTRAN?s NMT, vous pouvez faire plus que simplement traduire du contenu, vous pouvez pleinement comprendre, intégrer et construire des capacités de traduction pour répondre à vos besoins.




